
Welcome back to Teatime! This is a (semi-)weekly feature in which we sip tea and discuss some topic related to quality. Feel free to bring your tea and join in with questions in the comments section.
Tea of the week: Dragon Pearls by Teavana. My grandmother gave me some of this for my birthday a few years back, and it’s become one of my favorite (and most expensive!) teas since. Definitely a special occasion tea!
Edit: Teavana has stopped selling tea online after being bought by Starbucks. You know how I love a good chai, so how about the Republic Chai from Republic of Tea?

Today’s topic: Testing large domains
One challenge that intrigues me as much as it scares me is the idea of testing a product with a large domain of test inputs. Now, I’m not talking about a domain name or “big data”; instead, I mean a mathematical domain, as in the set of potential inputs to a function (or process). If you try to test every combination of multiple sets of inputs, or even every relevant one (barring a few you have decided won’t happen in nature), you’ll quickly run afoul of one of the key testing principles: exhaustive testing is impossible. Sitting down and charting out test cases without doing some prep-work first can quickly lead to madness and excessively large numbers of tests. That’s about where a BA I work with was when I offered to help, using the knowledge I’ve gained from my QA training courses.
The Project
The project’s central task was to automate the entry and processing of warranty claims for our products. We facilitate the collection of data and the shipping of the product back to the manufacturer as an added service for our customers, as well as handling the financial rules involved to ensure that everyone who should be paid is paid in a timely fashion. However, the volume of warranty claims was growing too large for our human staff to handle alone. Therefore, we set out to construct an automated system that would check certain key rules and disallow any claim to be entered that was likely to be rejected by the manufacturer.
The domain for this process is the cartesian join of the possible inputs: every manufacturer, every customer of ours, every warehouse that can serve the customer, every specific product (in case it’s on a recall), and every possible reason a customer might return a product (as they each have different rules). Our staff did a wonderful job of boiling them down to a test set that includes a variety of situations and distinct classes, but we were still looking at over 30,000 individual test cases to ensure that all the bases were covered by our extensive rules engine. What’s a test lead to do?
Technique: Equivalence partition
The first technique is pretty straightforward and simple, but if you’ve never used it before, it can be a lightbulb moment. The basic idea is to consider the set of inputs and figure out what distinguishes one subset from another. For example, instead of trying to enter every credit card number in the world, you can break them out into partitions: a valid Visa card, a valid Mastercard, a valid American Express, a card number that is not valid, and a string of non-numeric characters. Suddenly, your thousands of test cases can cut down to a mere five!
In essence, this is what the business folks did to arrive at 30,000 from literally infinite: they isolated a set of warehouses that represent all warehouses, and a set of customers that represent all types of customers, and a set of skus that represent all types of skus.
Technique: Separation of concerns
The next thing I did isn’t so much a testing technique as a development technique I adapted for testing. I realized that we were trying to do too much in one test: combinatorial testing, functional testing, data setup verification, and exploratory testing. By separating them into explicitly different concerns, we could drastically cut down on the number of test cases. I suggested to the BA that as part of go-live we get a dump of the data setup and manually verify it, eliminating the need to test all the possible rule scenarios for all possible manufacturers. I split my test cases into combinatory happy-path tests that make sure every potential input is tested at least once, and functional testing to verify that each rule works correctly. That cut way down on the number of cases. Divide and conquer!
Technique: Decision Tables
To create the functional tests, I used a technique called a decision table. Or well, a whole set of them, but I digress. Essentially, you identify each decision point in your algorithm, using them as conditions in the top portion. You then identify each action taken as a result, and list them in the bottom portion. You input test values (often true/false or yes/no, but sometimes numeric; you could have written C3 in the example as “transaction amount” and done “<$500” and “>$500” as your values).
If any of you have written out a truth table before, this is essentially the testing version of that. In the long form, this would have a truth table of the conditions, with the actions specified based on the algorithm. You can then take any two test cases that produce identical output and have at least one identical input and elide them together.
I started putting together a decision table for each return reason, with every rule down the left and every manufacturer across the top:
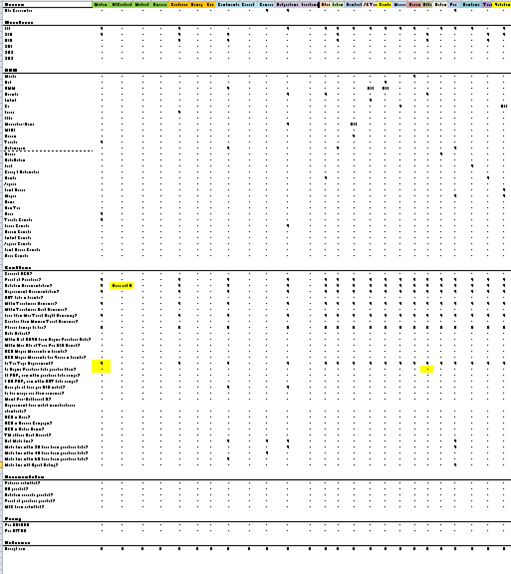
As you can see, it got really messy really fast! That was when I decided to try and use equivalence partitioning on the decision tree itself. I figured, not every manufacturer cares about every rule for every reason. If I did one table per reason, and only considered the test cases that could arise from the actual data, I would have something managable on my hands.
I sat down with a big list of manufacturers and their rules, and I divided that into a set of rules which can have a threshold (giving us two cases: valid or invalid) or a “don’t care” (giving two more cases: valid but the rule does not apply, and invalid but the rule does not apply). That cut down the number of manufacturers needed to test considerably, and allowed me to begin constructing a decision table.
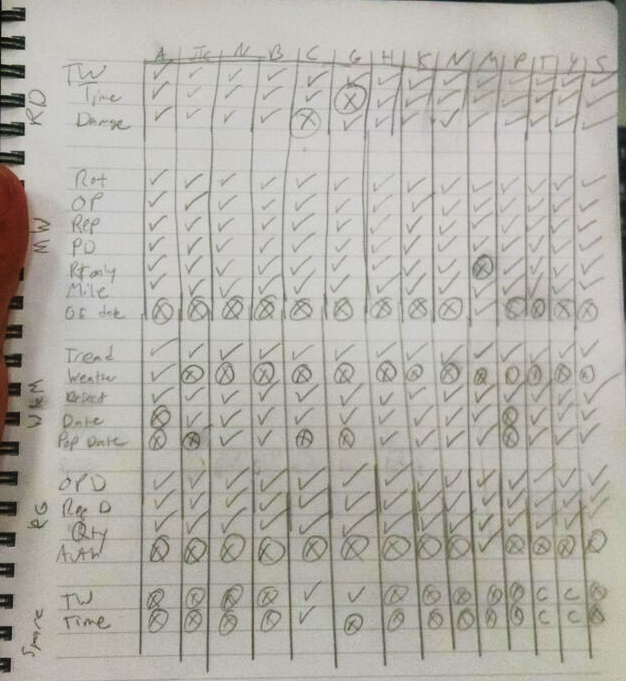
The output of that was a lot cleaner and easier to read:
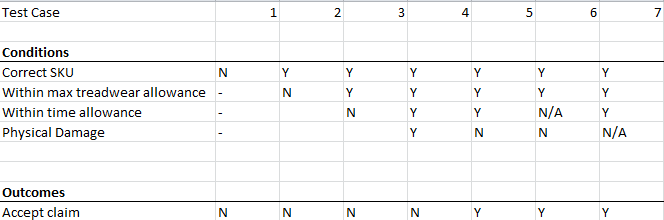
Technique: Classification Trees
The next technique is an interesting one. When I learned it, I didn’t think I’d ever use it; however, I found it to be immensely valuable here. A classification tree begins life as a tree, the top half of the diagram you’re seeing: you break out all the possible inputs, and break out the equivalence partitions of the domain of each in a nice flat tree like this. Then you draw a table underneath it.
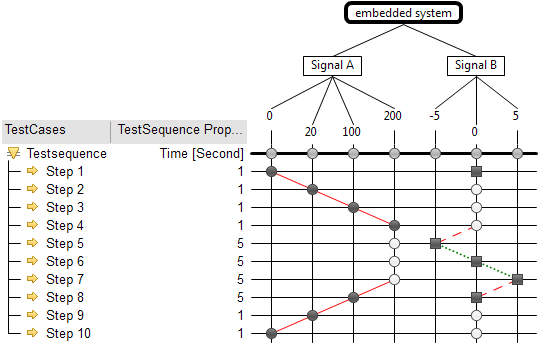
The ISTQB syllabus suggested using a specialized tool that can generate pairs, triples, et cetera according to rules you punch in, but I didn’t use it for this; my coverage criteria was just to cover each factor at least once, so I figure I need at least as many tests as the largest domain (the OEMs). I then went through and marked off items to make sure each one was covered at least once. You can do more with it, but that’s all I needed.
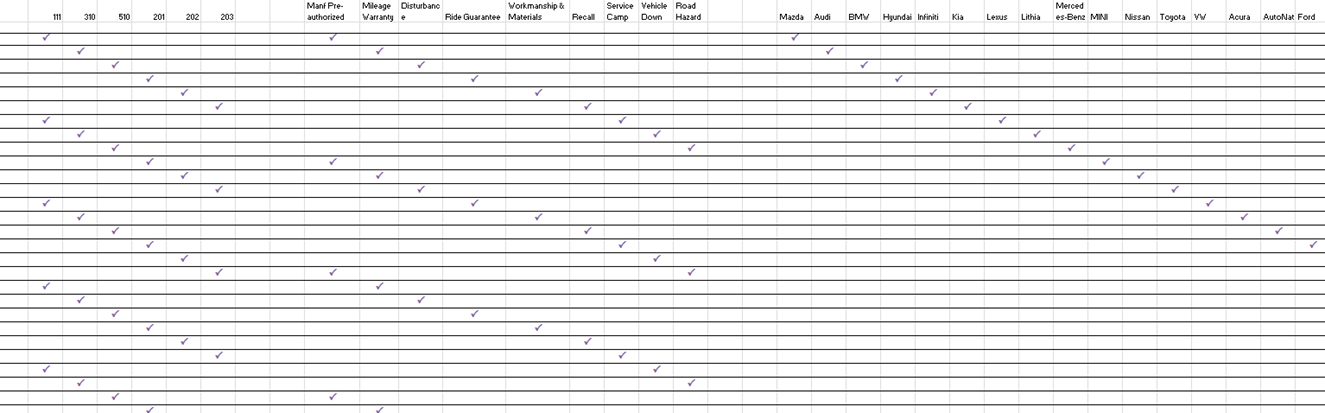
At last, we had a lovely set of combinatorial tests we could run:
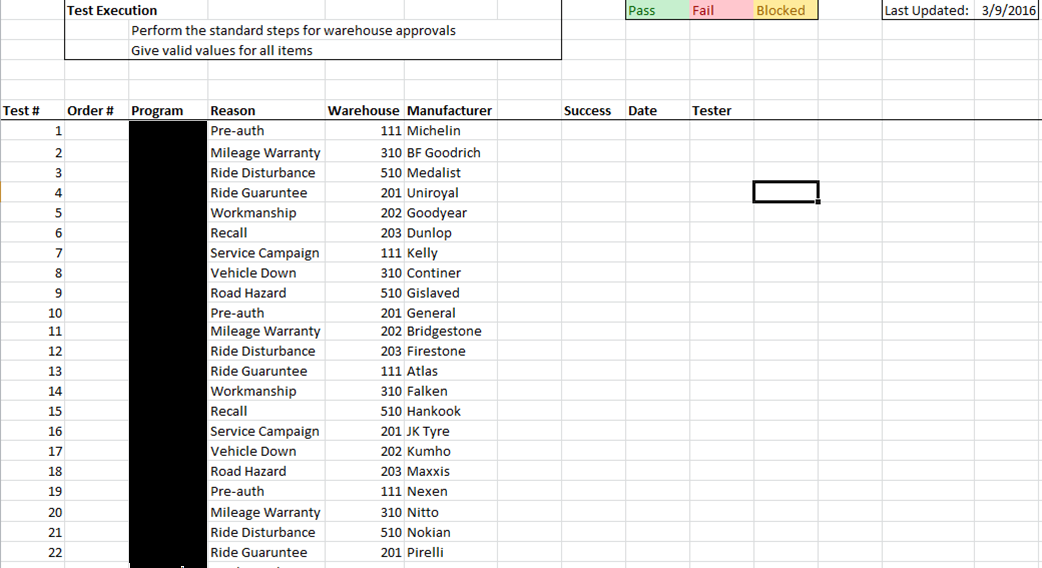
These tests, if you recall above, were to verify that various customer-reason-warehouse-manufacturer combinations were configured correctly. This would ensure that each of our representative samples were used in at least one test case, regardless of their data setup.
Have you ever faced a problem like this? What did you do?